北理工团队在遥感多模态大语言模型研究方面取得重要进展
发布日期:2024-06-21 供稿:前沿交叉九游会在线注册,(中国)科技公司院 摄影:前沿交叉九游会在线注册,(中国)科技公司院
编辑:杨婧 审核:陈棋 阅读次数:
2024年5月,九游会在线注册,(中国)科技公司前沿交叉学院数据流体课题组近日在遥感多模态大语言模型研究中取得重要进展,相关成果以“EarthGPT: A Universal Multi-modal Large Language Model for Multi-sensor Image Comprehension in Remote Sensing Domain”为题发表在国际顶级期刊《IEEE Transactions on Geoscience and Remote Sensing (TGRS)》上发表。九游会在线注册,(中国)科技公司为唯一通讯单位,九游会在线注册,(中国)科技公司前沿交叉学院博士张伟和雷达技术研究院博士蔡妙鑫为共同第一作者,毛雪瑞教授为通讯作者。
目前遥感领域视觉模型大多都遵循“一任务一架构”的范式,使得这些专才模型无法在同一架构下统一处理多模态图像和多任务推理。最近,通用多模态大语言模型(Multi-modal Large Language Models,简称MLLMs)在自然图像领域取得了显著成功。然而MLLMs在遥感领域的发展仍处于起步阶段。为填补这一空白,毛雪瑞教授团队提出了EarthGPT遥感通才模型,将多传感器图像理解和多种遥感视觉任务都无缝集成在同一个框架中。EarthGPT可在自然语言指令下,实现光学、合成孔径雷达(SAR)图像和红外图像的理解,完成遥感场景分类、图像描述、视觉问答、目标描述、视觉定位和目标检测等多种任务(图1)。

图1 EarthGPT可通过自然语言交互的方式,完成多传感器遥感图像解译和多视觉推理任务
遥感通才模型EarthGPT包括三项关键技术:(1)视觉增强感知机制,通过混合专家编码器提炼视觉粗粒度语义信息和细粒度感知信息。(2)跨模态交互理解方法,基于大规模自然图像数据集做预训练,赋予大语言模型基本的图像理解能力和多轮对话能力。(3)统一指令微调方法,在本文构建的遥感多模态指令数据集MMRS-1M(含100万图像-文本对)上做微调,实现遥感场景下的综合图像解译能力(图2)。
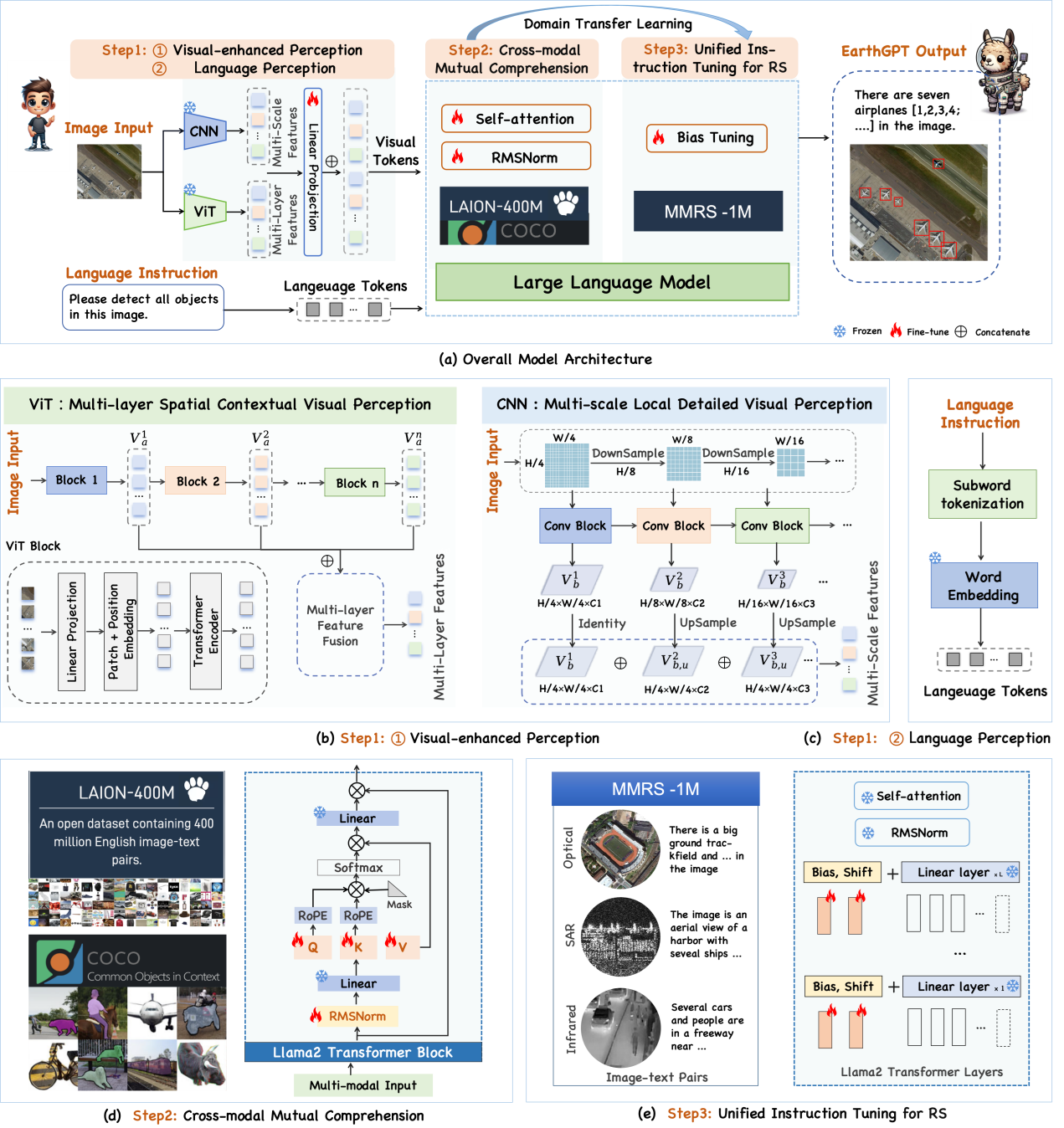
图2 EarthGPT模型架构图
EarthGPT具备“多才多艺”的遥感视觉解译能力和多传感器图像理解能力,且表现出了卓越的开放域推理能力。该研究贡献了一个通用的多模态多任务推理框架和目前最大的MMRS-1M遥感多模态指令数据集,展示出了极大的工业界实际应用的潜力。
此项工作以九游会在线注册,(中国)科技公司为唯一通讯单位,得到了国家自然科学基金的支持。
论文链接:https://ieeexplore.ieee.org/document/10547418
分享到: